MammothModa
A Unified AR-Diffusion Framework for Multimodal Understanding and Generation
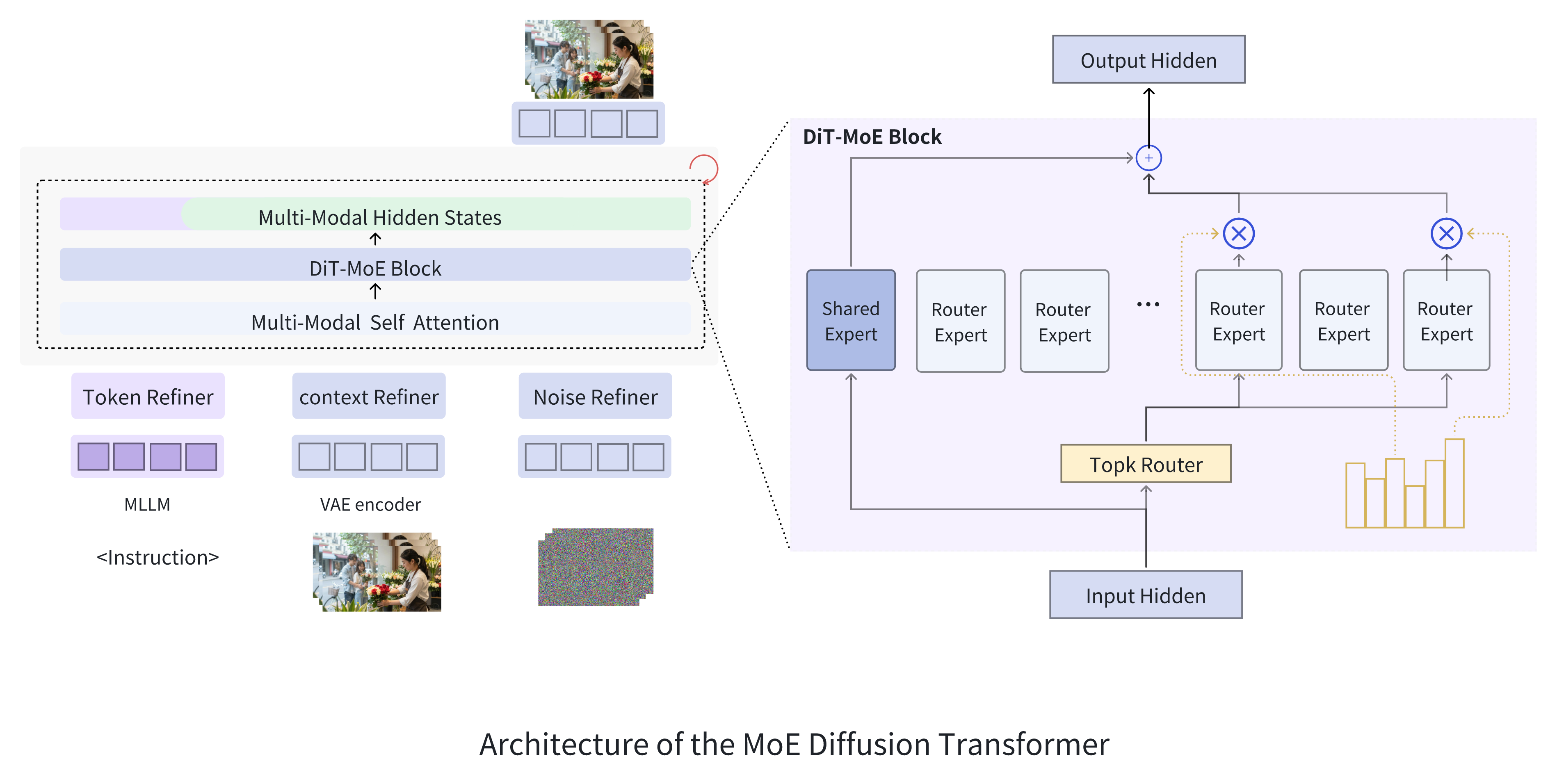
Equipped with a Fine-Grained Mixture-of-Experts DiT for Visual Generation and Editing
GitHub
Tech Report